目录
声音即文字 使用 OpenAI Whisper + SoundDevice 创建即时语音转录系统

上一篇 “走进 OpenAI Whisper 开源语音识别技术” 介绍了如何设计用 OpenAI Whisper 借助模型实现音频识别,本篇文章将在进一步,不使用音频文件,而是直接通过麦克风将同声语音做识别转录,并做简单输出。代码尽量简单,只做探索使用。
需要用到的开源库:
- whisper,OpenAI Whisper 是由 OpenAI 开发的一种自动语音识别(ASR)系统。Whisper 旨在识别并转录各种不同语言、口音和音频环境中的人类语音。
- sounddevice 和 soundfile(optional),sounddevice库提供了播放和录制声音的功能,而soundfile库允许读取、写入和处理音频文件
- numpy,用于对音频数据处理
- rich,用于在终端中创建富文本和美观格式的库,可参看 如何使用 Python rich 库让你的终端输出更加丰富多彩 文章
音频录入转文本输出

import sounddevice as sd
import soundfile as sf
import numpy as np
from queue import Queue
import threading
import time
import whisper
# 启动加载 whisper 语言训练模型
model = whisper.load_model("medium")
def record_audio(stop_event, data_queue):
'''
使用 sounddevice 库录制音频
'''
def callback(indata, frames, time, status):
'''
sounddevice.RawInputStream 回调函数
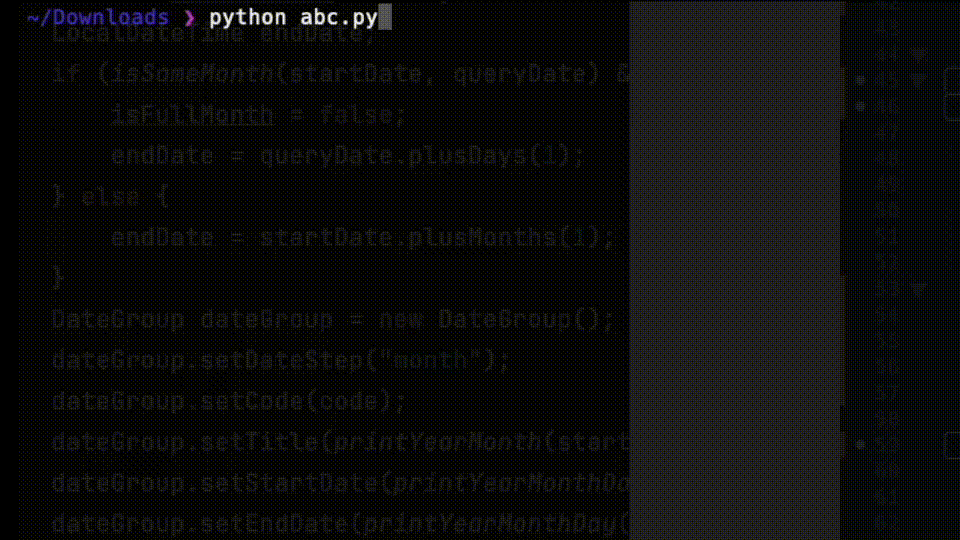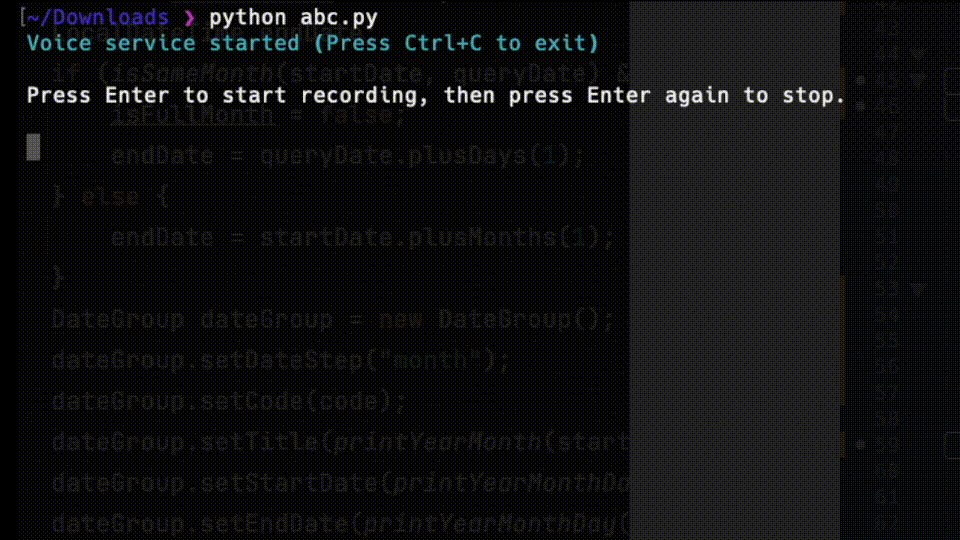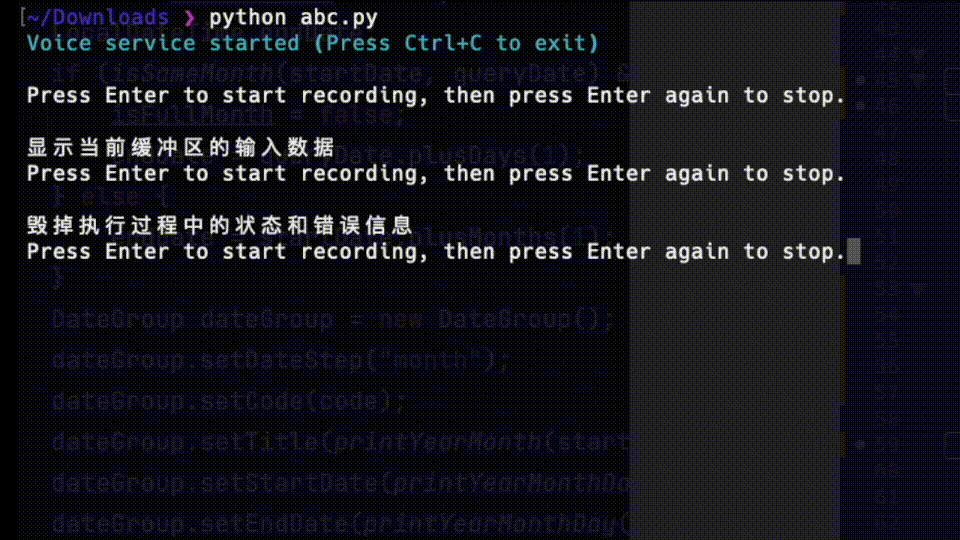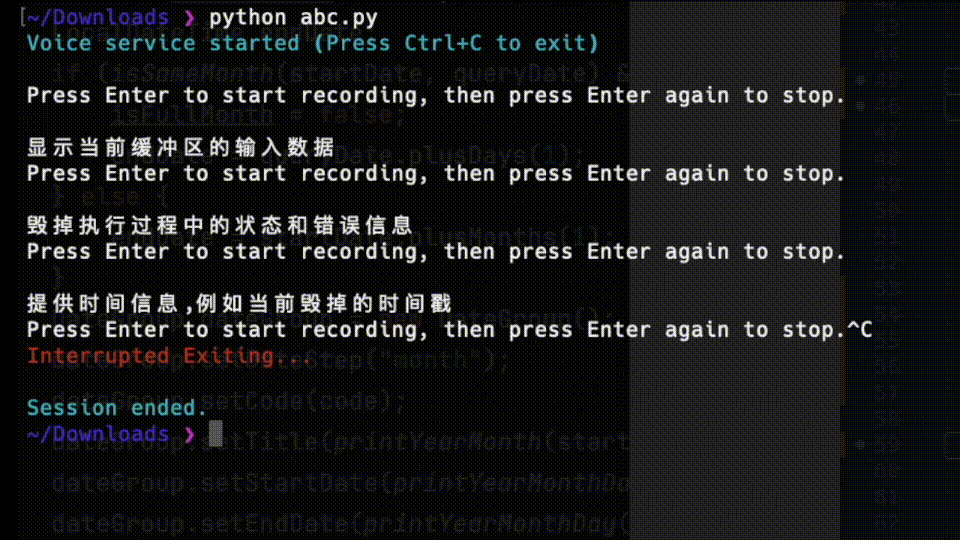
indata 是当前缓冲区的输入数据
frames 指示当前缓冲区中有多少帧数据
time 提供时间信息,例如当前回调的时间戳。
status 指示回调执行过程中的状态或错误信息
'''
# 如果 status 非空,即存在错误或警告,它会被打印到控制台
if status:
print(status)
data_queue.put(bytes(indata))
# 采样率16000,数据类型为16位整数,通道位1的单声道录音
with sounddevice.RawInputStream(samplerate=16000, dtype="int16", channels=1, callback=callback):
while not stop_event.is_set():
# 减轻 CPU 负担,每隔 0.1 秒检查 stop_event 状态
time.sleep(0.1)
if __name__ == '__main__':
print('Voice service started (Press Ctrl+C to exit)')
try:
while True:
print('Press Enter to start recording, again to stop')
# --------------- 启动音频录制 ---------------
# 创建队列存储音频字节,启动线程开始接受音频输入
data_queue = Queue()
stop_event = threading.Event()
recording_thread = threading.Thread(
target=record_audio,
args=(stop_event, data_queue),
)
recording_thread.start()
# 使用 input() 函数等待用户输入,暂停程序执行,知道用户按下回车键
input()
# 设置线程旗标为 True,停止录制过程
stop_event.set()
# 等待recording_thread线程完成,即record_audio函数完成其执行
# 在程序结束前的一个整理步骤,确保所有资源得以适当释放且没有遗留工作
recording_thread.join()
# --------------- 音频数据处理 ---------------
audio_data = b"".join(list(data_queue.queue))
# 用 numpy 库来将字节缓冲区(audio_data)转换为一个 NumPy 数组,并做类型转换和标准化处理
audio_np = (
np.frombuffer(audio_data, dtype=np.int16).astype(np.float32) / 32768.0
)
if audio_np.size > 0:
# 使用 openai whisper 识别音频字节数据,并输出到控制台
result = model.transcribe(audio_np, fp16=False)
print(result["text"])
sd.wait()
else:
print("No audio recorded. Please ensure your microphone is working.")
except KeyboardInterrupt:
print("\nVoice service ended")
上面的代码将录制的音频字节数据,转给 OpenAI Whisper 进行语音识别,然后打印到控制台中。
额外的一些操作
如果希望播放录制的音频,也可以使用 sounddevice 实现,但需要将录制和播放时的采样率设置成 44100,以达到正常的语速输出
# --- snip ---
# 采样率44100
with sounddevice.RawInputStream(samplerate=44100, dtype="int16", channels=1, callback=callback):
# --- snip ---
if audio_np.size > 0:
# 播放录制的音频
sd.play(audio_np, 44100)
sd.wait()
如果希望保存录制的内容到音频文件,可以使用 soundfile 实现,下面是片段代码
import soundfile as sf
# --- snip ---
if audio_np.size > 0:
# 写入录制的音频
sf.write('output.wav', audio_np, 44100, format='WAV')
总结
比较好的实现了语音转录,基于 whisper 的训练模型,语音识别度有很大提升,下一步应该思考如何把录制的文本,再转成音频播放出来