AI 智能体太烧钱?这 4 个技巧让 Token 成本直降 90%
- 一个让人心惊的成本数字
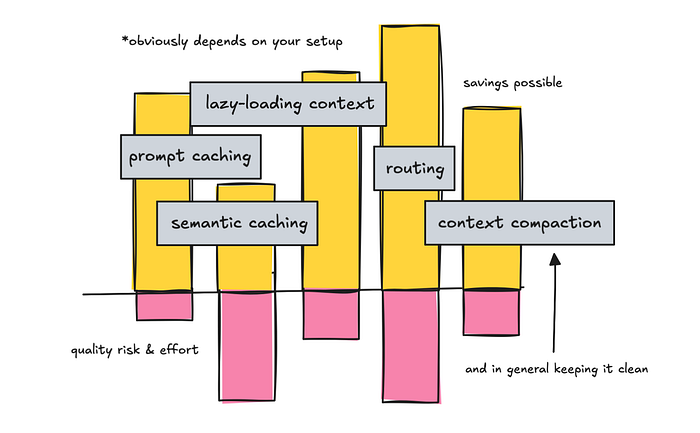
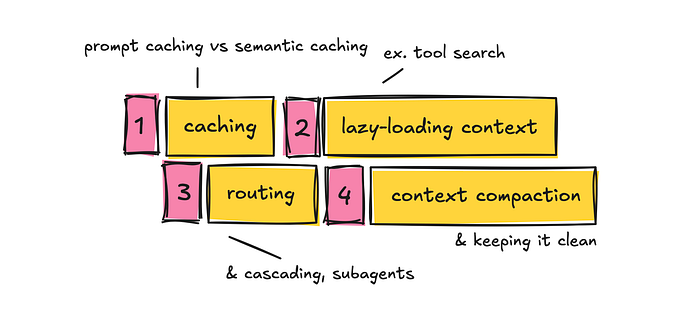
- 一、复用 Token:Prompt Caching 与 Semantic Caching
- 二、最小化固定开销:工具定义与记忆块
- 三、模型路由与级联:用小模型做简单事
- 四、保持上下文清洁:Compaction 与细粒度会话管理
- 实战:一个智能体的优化前后对比
- 权衡与风险
一个让人心惊的成本数字
你的第一个智能体可能只用了 500 token 的系统提示词和两个工具,但很快这些数字就会膨胀。Anthropic 之前泄露的 Claude 系统提示词大约 24,000 token,而 OpenClaw 用户曾报告向 Gemini 3.1 Pro 发送了超过 150,000 输入 token,只换来 29 个输出 token。
算笔账:一个未优化的智能体每天运行 100 条消息,每条 166K 输入 token,在 Gemini 3.1 Pro 上一个月大约 996 美元,在 Claude Opus 4.6 上更接近 2,490 美元。
但有一些技巧可以把成本压到 50-100 美元/月。本文覆盖四个方向的降本设计原则,包括 Prompt Caching、工具延迟加载、模型路由和上下文清洁,每个策略都附带交互式计算器的可视化参考。
一、复用 Token:Prompt Caching 与 Semantic Caching
LLM 的成本不仅来自调用频率太高,还来自反复为处理相同的 Token 买单。本节覆盖两种完全不同的缓存策略:K/V 缓存(底层的 Prompt Caching 机制)和语义缓存。
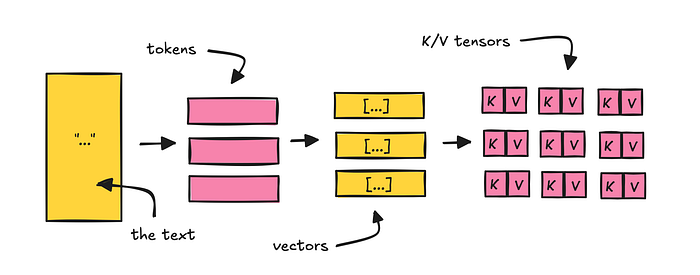
K/V Caching 与 Prefix Caching
在模型生成任何内容之前,它必须先处理提示词。提示词先被 token 化,然后转成向量,在每个注意力层中被投影为 K/V 张量。推理引擎在生成过程中会缓存这些张量——但关键在于:当响应结束后,可以不丢弃这个缓存。
下次请求进来时,检查提示词的相同部分是否已有缓存张量,如果有就直接加载,跳过重新处理。经济意义:假设处理 2,000 token 需要 1 秒,你的系统提示词是 10,000 token——每次 LLM 调用省 5 秒。
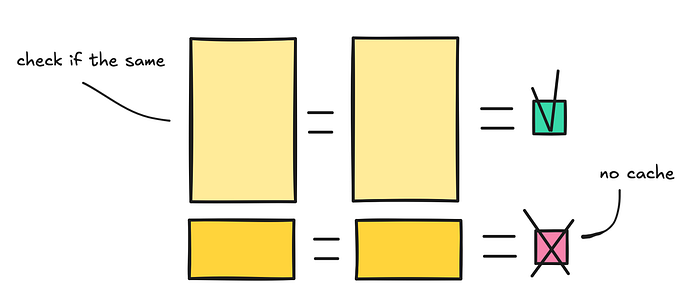
关键限制:缓存匹配要求输入完全一致。多一个空格、重新排序的工具定义、放错位置的时间戳——都会导致缓存失效。此外,存储 K/V 张量不免费,大多数提供商的 TTL 窗口约为 5-10 分钟。
自托管:vLLM 前缀缓存
如果你自托管开源模型,使用 vLLM 的 --enable-prefix-caching 标志启用缓存。缓存层将提示词按块哈希,存储 K/V 张量。相关参数:
--block-size:调整每个块的 token 数--kv-cache-memory-bytes:显式设置每 GPU 的 KV 缓存大小
其他方案:SGLang + RadixAttention、LMCache。
API 提供商:各家的规则
| 提供商 | 缓存机制 | 节省幅度 |
|---|---|---|
| OpenAI | 自动启用(≥1,024 token),精确前缀匹配,前 256 token 用于路由 | 缓存输入最多 90% off |
| Anthropic | 需手动 cache-control 参数,TTL 5-10 分钟(可延长至 1 小时,但 2 倍存储费) | 缓存输入有折扣,但要付存储费 |
Semantic Caching:按「意思」匹配
与 Prompt Caching 不同,Semantic Caching 不是匹配精确 token,而是匹配语义相似性。
流程:
- 将用户输入转为 embedding 向量
- 和之前缓存的请求向量比较相似度
- 如果足够接近(如余弦相似度 > 0.95),直接返回缓存的响应
适用场景:用户问题高度重复的任务(如客服 FAQ、内容审核、数据分类)。 不适用:所有查询都需要精确不同答案的情况。语义缓存会牺牲一定的「新鲜度」。
二、最小化固定开销:工具定义与记忆块
每次 LLM 调用都会带上系统提示词和工具定义,这部分 token 是每次都要付的固定成本。如果每个智能体有 30 个工具、每个工具定义 500 token,那就是 15,000 token 的固定开销。
Lazy-Load 工具
思路很简单:不是所有工具在所有场景下都有用。
将 30 工具的智能体按功能域分组:
─ 核心工具集(始终加载)
├─ read_file, write_file, search(~1,000 token)
└─ terminal, web_search(~800 token)
─ 按需加载的工具集
├─ 代码审查工具集(仅需要时加载)
├─ 数据库操作工具集(仅需要时加载)
└─ 浏览器自动化工具集(仅需要时加载)
通过路由层智能判断需要哪些工具集,在请求到达编码智能体之前动态组合。这样每次调用只带必要工具,固定 token 开销从 15K 降至 ~2K。
记忆快照(Memory Snapshots)
不要每次都把全部历史记忆塞进上下文。只注入当前任务相关的记忆快照。可以基于时间窗口(只看最近 N 轮对话)或基于语义检索(仅注入与当前问题向量相似的历史片段)。
三、模型路由与级联:用小模型做简单事
最直观的降本方式:让复杂问题走大模型,简单问题走小模型。
路由策略
用户请求 → 分类器(小模型)→
├─ 简单任务(分类、提取、格式化)→ Gemini Flash / GPT-4o Mini
├─ 中等任务(推理、分析)→ GPT-4o / Claude Sonnet
└─ 复杂任务(代码生成、深度推理)→ Claude Opus / o3
级联(Cascading)
级联更激进:先试最便宜的模型,如果置信度不够再升级。
def cascade(query, max_depth=3):
models = ["gemini-flash", "sonnet", "opus"]
for i, model in enumerate(models):
result = call_model(model, query)
if i == max_depth - 1:
return result
if confidence_score(result) > 0.9:
return result
# 置信度不够,自动升级
做对的事
路由和级联节省显著但引入新风险:
- 小模型可能误分类重要问题
- 错误的早期路径决策导致「垃圾进垃圾出」
- 监控和调试复杂度上升
建议:从简单路由开始(匹配关键词到对应模型),逐步过渡到基于 embedding 的语义路由。
四、保持上下文清洁:Compaction 与细粒度会话管理
脏乱的上下文不仅让模型表现变差,还会浪费大量 token。
主动 Compaction
Claude Agent SDK 中的 Compaction 功能:当上下文窗口接近满时,自动将之前的对话压缩为摘要。但摘要会丢失细节——所以需要将 Compaction 与外部文件系统结合(详见 Harness Engineering 方案)。
分步会话策略
不要在一个会话里让智能体完成所有事。拆分为:
- 分析会话:接收需求 → 输出分析文档
- 规划会话:分析文档 → 输出执行计划
- 执行会话:执行计划 → 输出结果
每个会话只带前一阶段的输出摘要,而不是完整对话历史。
实战:一个智能体的优化前后对比
| 优化项 | 优化前 | 优化后 |
|---|---|---|
| 系统提示词 | 24,000 token | 8,000 token(启用缓存) |
| 工具定义 | 15,000 token(30个工具) | 3,000 token(按需加载) |
| 历史上下文 | 每次带全部历史 ~100K | 仅带摘要 ~5K |
| 模型 | 全部用 Opus | 80% Flash + 20% Opus(路由) |
| 月成本 | ~$2,490 | ~$80 |
权衡与风险
每个节省策略都带来权衡:
| 策略 | 节省 | 风险 |
|---|---|---|
| Prompt Caching | ⭐⭐⭐ | 缓存管理复杂度 |
| Semantic Caching | ⭐⭐ | 返回过期结果 |
| Lazy-Load 工具 | ⭐⭐ | 首次调用延迟增加 |
| 模型路由 | ⭐⭐⭐⭐ | 小模型误判风险 |
| 级联 | ⭐⭐⭐⭐⭐ | 延迟增加 |
| Compaction | ⭐⭐ | 细节丢失 |
没有银弹。最佳方案是按实际用量组合使用——先用 Prompt Caching 这个最快见效的策略,再逐步引入其他优化。