Claude Code 12 大最佳实践:从跟风编程到 Agent 工程
- 前言
- 1. 你的 CLAUDE.md 可能适得其反
- 2. 别再像聊天窗口一样用 Claude Code
- 3. 上下文是资源,像资源一样对待它
- 4. Hooks 在 Agent 循环之外运行
- 5. 减少 84% 的权限弹窗
- 6. “随时随地运行几十个 Claude”
- 7. ultrathink 不是噱头
- 8. 本地自动化,CI 做不到的事
- 9. 不中断主任务提出旁路问题
- 10. 让技能值得写的核心部分
- 11. 让”完成”真正代表完成
- 12. 一个参数让 SDK 调用快 10 倍
- 总结
前言
Claude Code 是 Anthropic 推出的终端 AI 编程助手,但很多人只是把它当聊天窗口用。
2026 年 3 月,shanraisshan/claude-code-best-practice 登顶 GitHub Trending 日榜第一。这个仓库由 Claude Code 的缔造者 Boris Cherny 审阅,整理了 11 个类别的 69 条实用建议,副标题是:”从跟风编程(vibe coding)到 Agent 工程”。
我通读了一遍,筛选出 12 个真正改变我工作方式的模式,结合自己的实践整理如下。
1. 你的 CLAUDE.md 可能适得其反
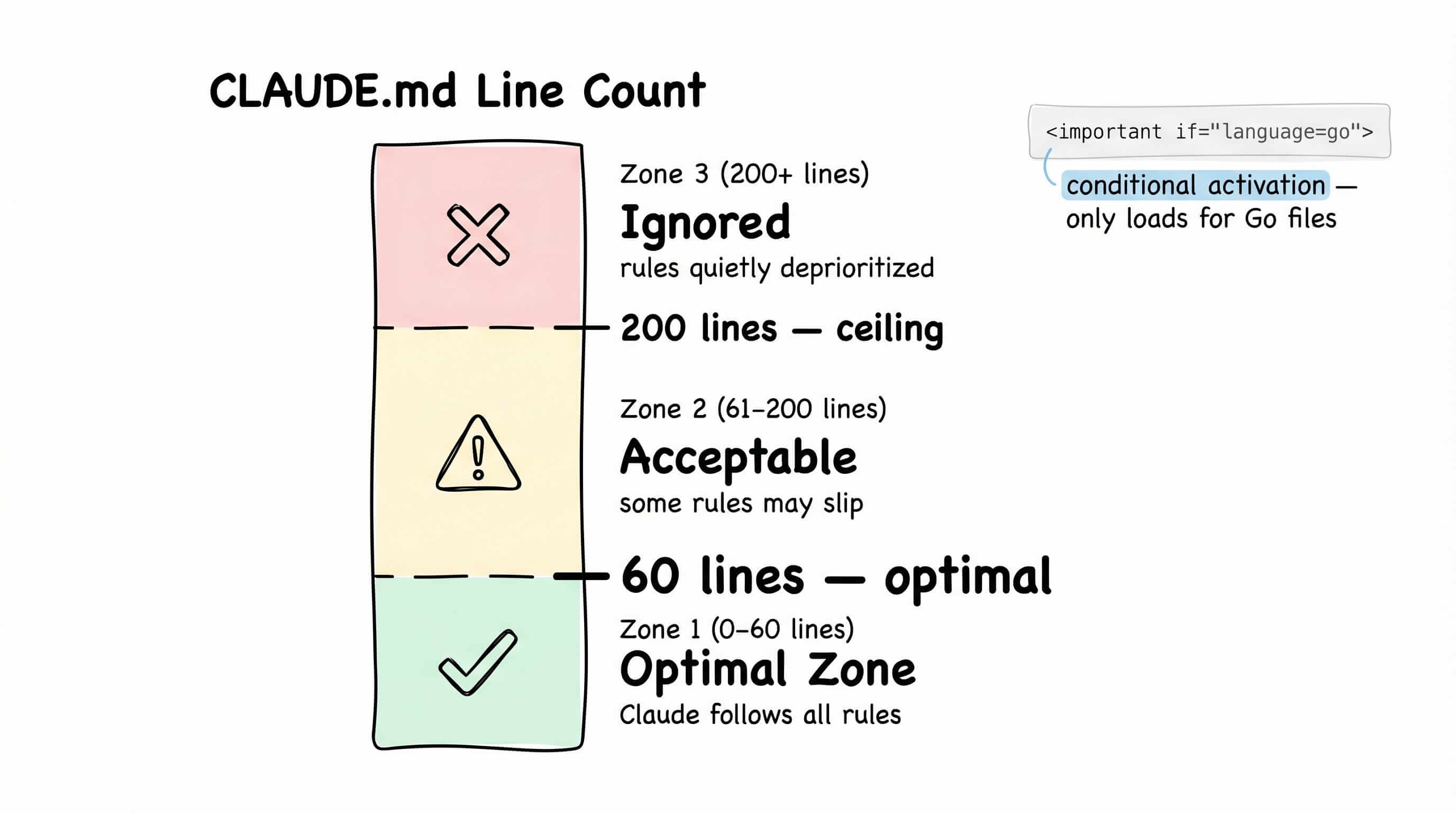
大多数人把 CLAUDE.md 当配置文件用:越长越详细越好。我之前的有 500 多行——代码风格、提交格式、测试要求、变量命名、包组织结构都有。
Claude 忽略了后半部分。不是每次都忽略,而是频繁到你没法依赖它。
研究发现:60 行是最优的,200 行是上限。 超过之后,文件靠后的规则会被悄悄降权处理。Claude 的工作注意力有限,500 行的文件要求它同时记住太多约束。
解决办法不是删规则,而是让规则只在相关时才出现。使用 <important if="language=go"> 语法——当 Claude 在处理 Go 文件时,这个标签内的规则才可见;当它在写 Python 脚本时,整个块对当前 session 来说不存在。
对于多层级 Go 服务,推荐这样的文件结构:
my-service/
├── CLAUDE.md # 根目录:通用规则,约 30 行
├── api/
│ └── CLAUDE.md # REST 约定、错误码
├── internal/
│ └── CLAUDE.md # 包命名、接口模式
└── cmd/
└── CLAUDE.md # 参数解析、日志初始化
internal/CLAUDE.md 里使用条件规则:
<important if="language=go">
- 不要裸 goroutine,使用 errgroup 或 WaitGroup 管理生命周期
- 通道容量 > 0 需要行内注释说明原因
- context 必须是第一个参数,命名为 ctx
</important>
总行数保持可控,每条规则只在真正相关时触发。
2. 别再像聊天窗口一样用 Claude Code
这个习惯花了我很长时间才改掉:每次以全新提示词开始,重新建立所有规则。
“帮我审查这个 PR。只读文件,别改任何东西。重点关注 internal/ 包。用项目的错误处理规范。”
每次都要。而且每次。
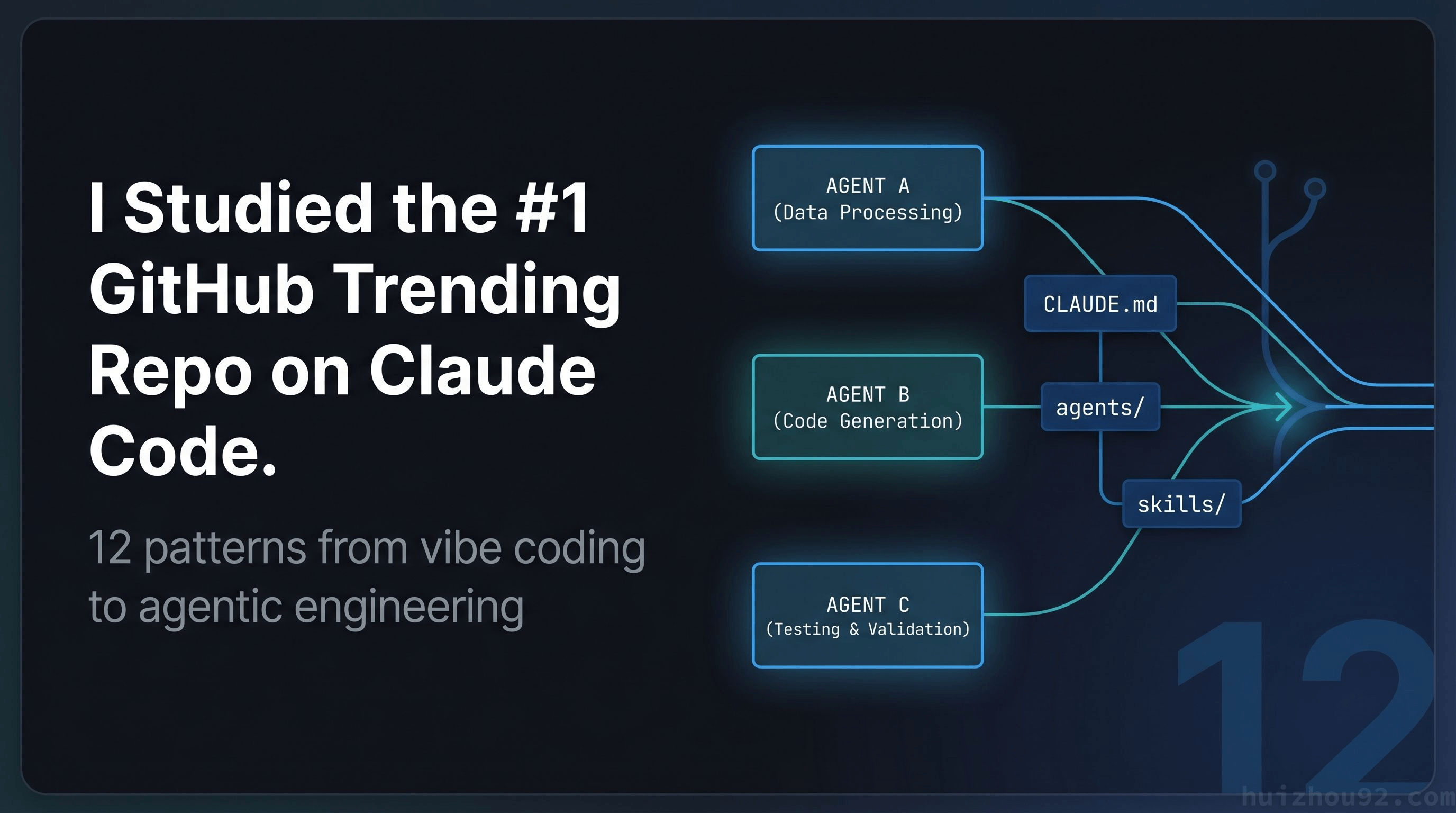
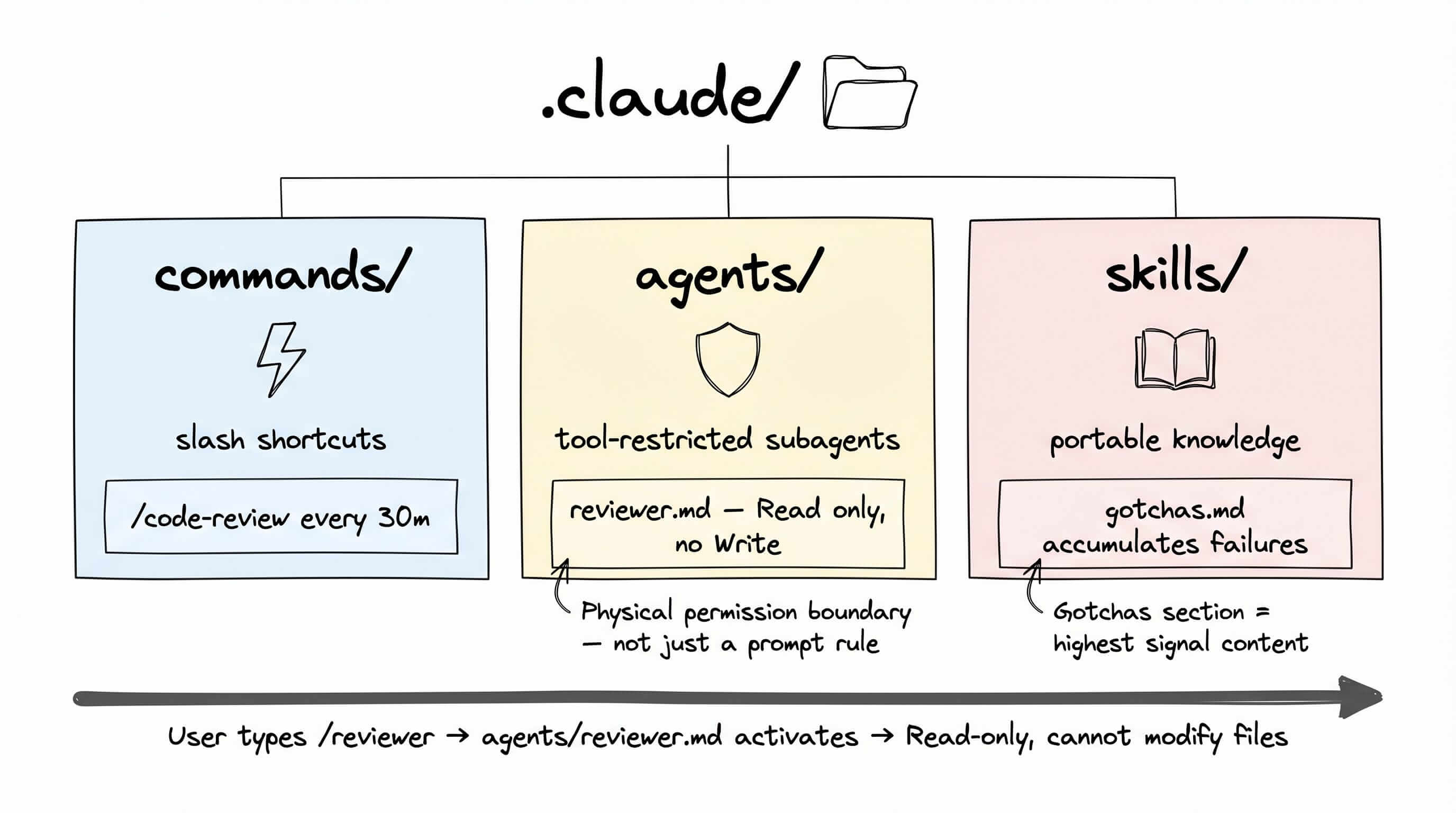
替代方案:把 Claude Code 当作编排系统而非聊天界面。 .claude/ 目录支持三种配置类型:
commands/:可复用的工作流快捷方式,存为斜杠命令agents/:专用子 Agent,工具访问权限受限skills/:跨项目移植的知识模块
一个杀手级例子:在 .claude/agents/ 里创建 reviewer.md——一个专用 Agent,只有读取权限,没有写入工具,没有 shell 执行,没有网络访问。
这个 Agent 物理上无法修改文件。不管你在对话里要求它做什么都无所谓。提示词不再约束——是配置在约束。
“只读文件,别改任何东西”这句话已经从我的所有提示词里删除了。因为不再需要了。
3. 上下文是资源,像资源一样对待它
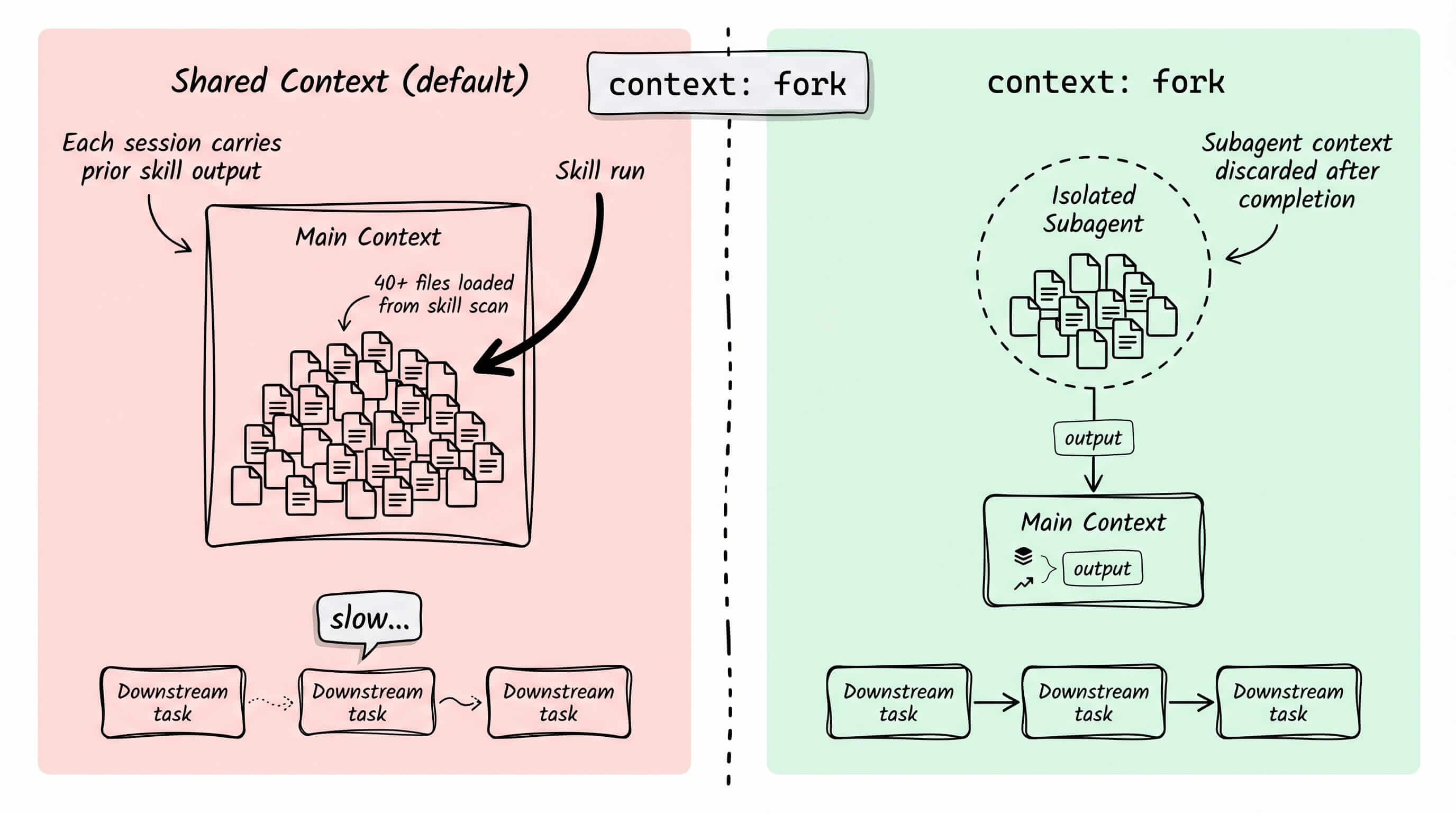
Skills 默认共享主 Agent 的上下文。这比听起来重要得多。
我有一个代码质量分析 skill,会读取 40 个文件生成报告。运行后,那个 session 里后续的每个任务都变重了——Claude 带着所有文件内容,即使回答完全不相关的问题也是如此。响应变慢了,而且那种”不那么锐利”的感觉很难归因到具体原因。
一行代码就能解决:
context: fork
这个 skill 在隔离的子 Agent 中运行。完成后,那部分上下文被丢弃。主 Agent 只看到输出——干净的摘要、发现列表,不管 skill 设计要返回什么。
无需手动 /compact,无需开新 session 清理。
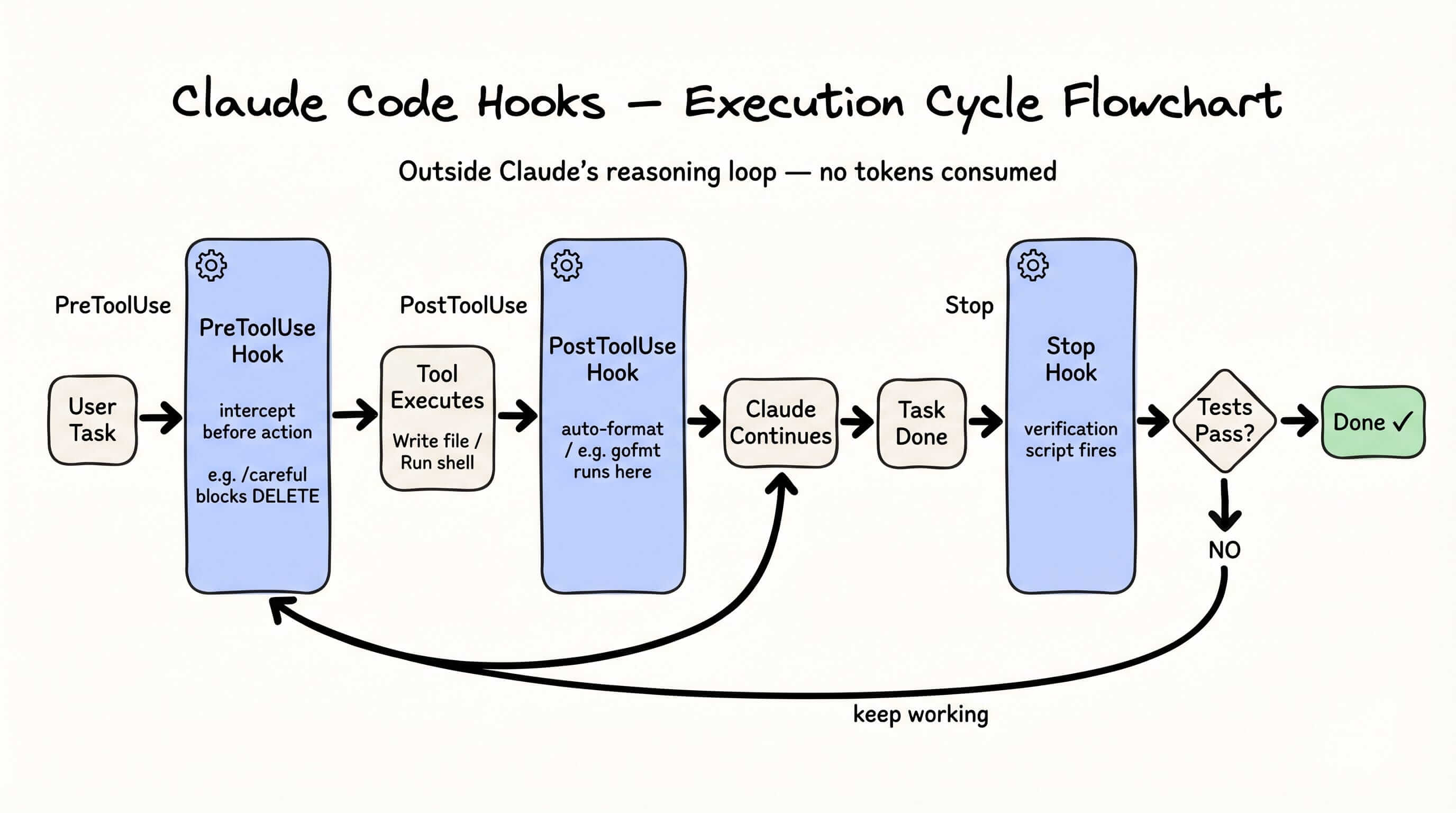
4. Hooks 在 Agent 循环之外运行
PreToolUse、PostToolUse、Stop——三个大多数 Claude Code 用户从未配置过的钩子点。
它们在架构上的有趣之处是:在 Claude 的主要推理循环之外执行。不消耗 token,不中断任务。它们附着在 Claude 动作上的旁路自动化,不是 Claude 动作的一部分。
几个具体用法:
- 写入后自动格式化:PostToolUse 钩子在每次写入 Go 文件后运行
gofmt,格式化从不是你要 Claude 做的事——它自然发生。 - 防护式破坏性操作:
/careful模式激活一个 PreToolUse 钩子,拦截所有不可逆操作——文件删除、覆盖、分支强制推送——需要明确确认才能执行。 - 完成验证:详见第 11 个模式。
5. 减少 84% 的权限弹窗
Claude Code 默认每个 shell 命令都需要批准。这对安全是正确设置,但对流程是错误设置。
/sandbox 在隔离环境中运行 shell 命令。每个命令的爆炸半径被限制,因此批准门槛大幅降低。实际效果:减少 84% 的权限弹窗。
代价是实打实的——沙盒命令的系统访问有限。但对大多数编码任务来说,沙盒边界从未触及,而中断消失了。
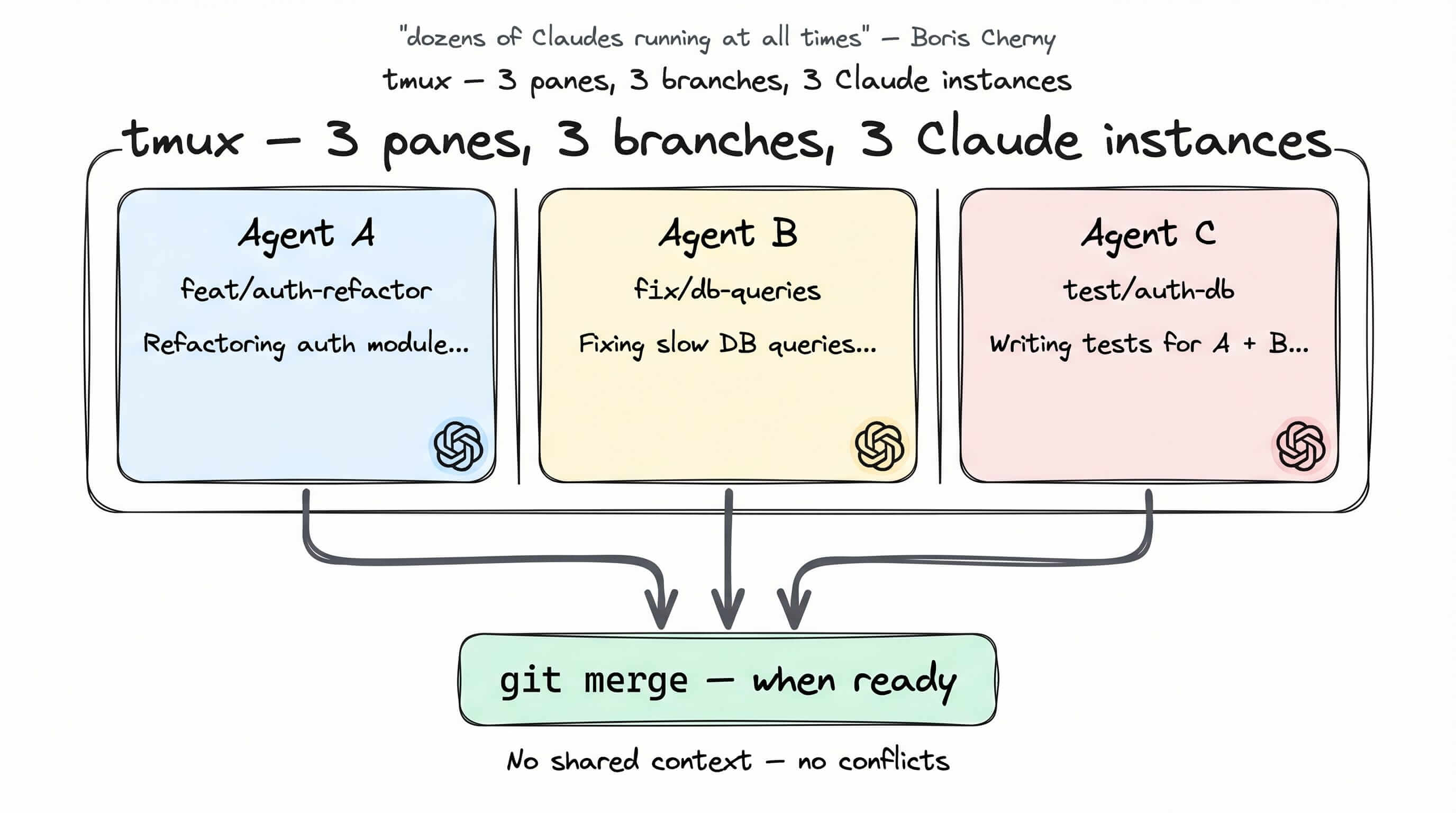
6. “随时随地运行几十个 Claude”
这是 Boris Cherny 对自己工作流的描述。不是夸张。
claude -w
claude -w 在 git worktree 内启动 Claude——一个隔离的、位于单独分支上的工作目录。结合 tmux 的多面板,你就拥有同时运行的、独立的 Claude 实例——每个有自己的上下文、自己的分支、自己的任务。
Agent A 在重构 auth 模块。Agent B 在修复数据库层。Agent C 在给两者写测试。没有实例共享上下文,没有实例冲突。它们的变更在准备合并前都在独立的分支上。
从一次等一个 Claude 回复,到同时运行十几个——这个转变很可能是跟风编程和 Agent 工程之间最显著的差异。
7. ultrathink 不是噱头
在任务描述中任何地方输入 ultrathink 这个词,Claude 就会进入更高努力的推理模式。这是扩展思考的自然语言触发器——无需配置更改,无需模型切换,只是一个词放进提示词里就行。
不是所有任务都需要它。大多数任务不需要。
我曾在设计一次服务拆分时使用它。普通模式给出了三个不错的选项。使用 ultrathink 后,Claude 浮现了两个我之前没考虑到的约束——跨服务事务边界和现有监控系统的接入成本。最终选择与普通模式推荐的完全不同。
8. 本地自动化,CI 做不到的事
/loop 30m /code-review
每 30 分钟运行一次代码审查工作流。无需人工介入。最长间隔 1 小时,最长持续 3 天。
CI/CD 自动化的是代码合并后的事。/loop 自动化的是开发过程中的事——而且它能做 CI 根本做不到的事,因为它能访问你当前的工作状态。
CI 流水线看到的是 diff(差异)。基于循环的审查知道你在这次 session 中一直在做什么、之前出现过什么问题、确立了哪些约束。
我曾在周五下午让一个循环跑过周末。周一早上,我不在时的问题已被标记出来了,PR 摘要也起草好了。
大多数开发者不知道 Claude Code 原生就有这个能力。
9. 不中断主任务提出旁路问题
你在跑一个重构,90 分钟了。想问一个不相关的问题——关于另一个文件、另一个问题。中断意味着丢失上下文。但问题需要答案。
/btw <你的问题>
/btw 把问题加入队列。Claude 继续当前任务,记下你的问题,在自然的暂停点处理它,然后回到之前的地方。
一旦用过它,停下整个任务去问一个旁路问题感觉就像浪费时间。
10. 让技能值得写的核心部分
如果你在给团队写 skills,Thariq——这个仓库 skill 部分的贡献者之一——有一条建议:
“任何 skill 中信号最强的部分是 Gotchas(踩坑记录)。”
不是概述。不是使用示例。是踩坑记录。
Gotchas 部分记录了 Claude 在实际使用中遇到的失败模式。不是你预期的边界情况——是真实失败、随时间积累、发生时就被写下来的失败。它们的信噪比远高于解释性文字,因为它们是具体的、可验证的、可叠加的。每次你记录的失败都会成为未来的预防。
先写 Gotchas 部分。每次 Claude 失败就更新。让它成为 skill 文档中最核心的产物。
11. 让”完成”真正代表完成
Claude 会告诉你任务已完成。但这不代表它真的完成了。
我让 Claude 写一组 API 处理器。它说完成了。我看了代码——三个处理器中有两个的错误处理是空的。err != nil 后面什么都没跟。
用 Stop 钩子连接一个验证脚本——运行测试套件、检查预期文件是否存在、调用 API 端点并验证响应。如果验证失败,任务状态回滚,Claude 继续工作直到通过。
在跨夜或跨多次 session 运行的自动化工作流中,这是可信输出和仍需要手动检查的输出之间的区别。
12. 一个参数让 SDK 调用快 10 倍
当通过 Agent SDK 以编程方式使用 Claude 时——不是在交互式 CLI 中——加上 --bare。
claude --bare --prompt "analyze this file"
上下文发现是 Claude 的启动过程:定位 CLAUDE.md 文件、加载配置、检查环境。在交互式 session 中,这发生一次。在批量自动化中,它在每次调用都发生。
--bare 跳过它。启动时间减少最高 10 倍。
单次调用时区别几乎不可察觉。但我有一个每日代码分析管道——大约 300 个文件,每个文件一个 Agent 并行运行。配置前约 40 分钟,配置后 18 分钟。同样的基础设施,同样的工作负载。
总结
看完所有 69 条建议后,跟风编程和 Agent 工程之间的真正差距不在于不同的工具,而在于同样的工具以不同的方式使用。
| 跟风编程 (Vibe Coding) | Agent 工程 (Agentic Engineering) | |
|---|---|---|
| 约束来源 | 你每天写的提示词 | 配置文件 + 权限限制 |
| 工作方式 | 描述 → 尝试 → 纠正 → 重复 | 预设规则 → 自动执行 → 自动验证 |
| 上下文管理 | 手动 /compact | context: fork 自动清理 |
| 权限控制 | 每次你手动批准 | Agent 物理上无权做某些操作 |
| 可复用性 | 每次重写提示词 | Skills / Commands / Agents |
| 并行度 | 一次一个对话 | 几十个 Agent 同时运行 |
| 验证方式 | 你肉眼检查 | Stop 钩子自动验证 |
做这些事的工具——agents、skills、hooks、worktrees、loops——Claude Code 自带了。它们不是高级功能。大多数人从未发现它们。
仓库地址:shanraisshan/claude-code-best-practice,仍在活跃维护,值得通读。
本文翻译改编自 huizhou92 在 Level Up Coding 的文章,由 Boris Cherny 审阅的 69 条建议浓缩为 12 个核心模式。
版权所有,本作品采用知识共享署名-非商业性使用 3.0 未本地化版本许可协议进行许可。转载请注明出处:https://www.wangjun.dev//2026/05/claude-code-best-practices/