Context Engineering:AI Agent 上下文工程的完整指南
- 1. 什么是 Context Engineering
- 2. 上下文腐烂与”中间丢失”
- 3. 四大核心策略
- 4. Agent 的四种失败模式
- 5. 系统提示与工具定义的最佳实践
- 6. 实践:频繁有意识压缩
- 7. 主流平台的做法对比
- 8. 总结
1. 什么是 Context Engineering
如果你一直在用 AI Agent 构建东西,大概已经注意到一个问题:Agent 在前几步表现得很好——选对工具、推理清晰、按计划推进。但到了第 15 或 20 步,就开始变得”马虎”——忘记你要求什么、调用莫名其妙的工具、输出质量断崖式下降。
大多数人第一反应是”模型不行”。但通常,问题出在模型看到的内容上。
组织模型看到的内容,就是 Context Engineering(上下文工程)。它正在成为构建 AI Agent 最重要的技能之一。
本文作者 Marina Wyss 是 Twitch 的高级应用科学家,从事 Gen AI 工作。她梳理了大量工程博客、会议演讲、学术论文和实践报告,提炼出了这份完整的上下文工程指南。

Prompt Engineering 是写出好指令的技能——清晰地表达、给好的示例、告诉模型扮演什么角色。这在跟 ChatGPT 对话时效果很好。
但当你从聊天机器人转向 Agent 时,Prompt Engineering 就远远不够了。原因很简单:Agent 不只是回答一个问题——它要自主地浏览网页、调用 API、写代码、运行命令,一步一步地,有时几十步。每一步的输出都加到模型的上下文中。而上下文是有限的。
Anthropic 的工程团队这样定义:上下文是采样 LLM 时包含的 token 集合,上下文工程就是优化这些 token 的效用,以持续达成期望的结果。
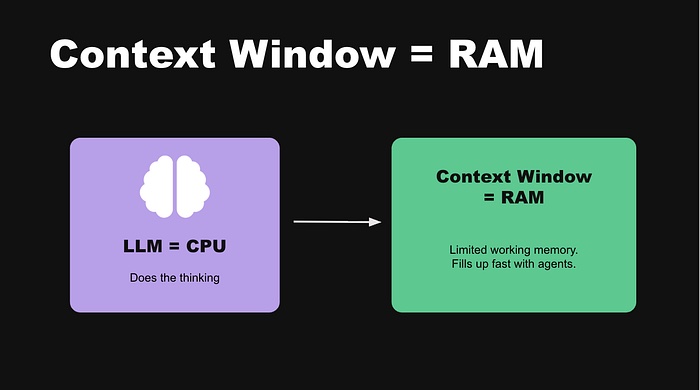
LangChain 有一个很好的类比:把 LLM 想象成一种新型操作系统——模型本身是 CPU(负责思考),上下文窗口是 RAM(工作记忆),模型当前能看到和推理的所有内容都在这里。
就像电脑 RAM 满了会变慢,Agent 的推理能力在上下文窗口变得拥挤时也会退化。
2. 上下文腐烂与”中间丢失”
Chroma 发表过一项重要研究,评估了 18 个前沿模型——GPT-4.1、Claude 4、Gemini 2.5、Qwen3 等。结果发现:每个模型的性能都随输入长度增长而下降,即便远未达到官方的上下文窗口上限。一个标称 200K token 的模型,可能在 50K token 时就出现明显的性能退化。退化是渐进的,不是突然断崖。
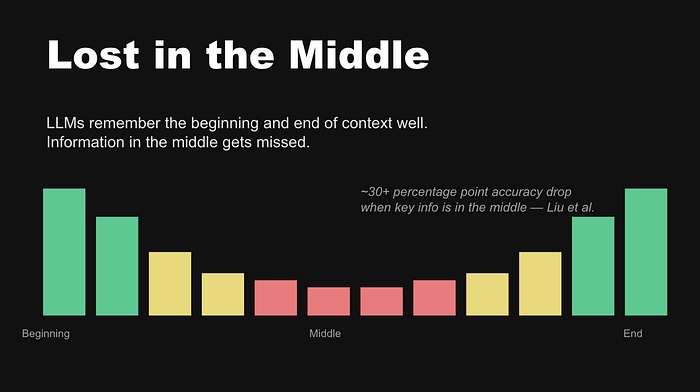
这就是著名的 “Lost in the Middle” 现象。Liu 领导的研究团队发现,LLM 呈现 U 型注意力曲线——开头和结尾的信息记得好,但中间的信息会被忽略。当相关信息从上下文开头移到中间时,准确率会下降超过 30 个百分点。
这意味着一件事:如果初始指令被五万 token 的工具输出淹没,这些指令实际上就消失了。
实践者总结的经验法则:Claude Code 用户在上下文窗口用到 40%-60% 时就会观察到输出质量下降——远未触及硬性限制。
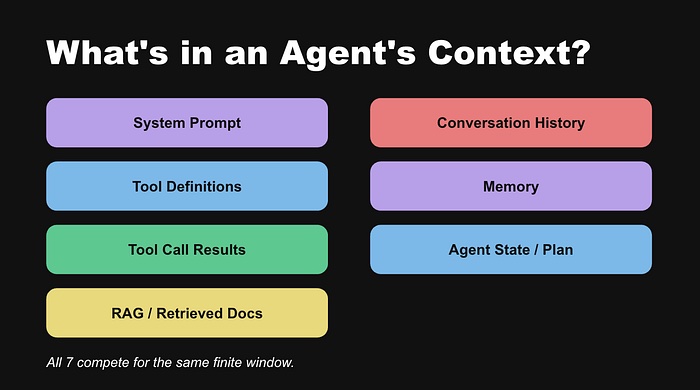
Agent 上下文中竞争的七类信息:
- 系统提示 — Agent 的身份和行为规则
- 工具定义 — 每个工具的 schema
- 工具调用结果 — 每次调用的输出
- 检索知识 — 从 RAG 拉取的文档
- 对话历史 — 整个会话的完整记录
- 记忆 — 短期和长期记忆
- Agent 状态 — 当前计划、待办事项、进度
3. 四大核心策略
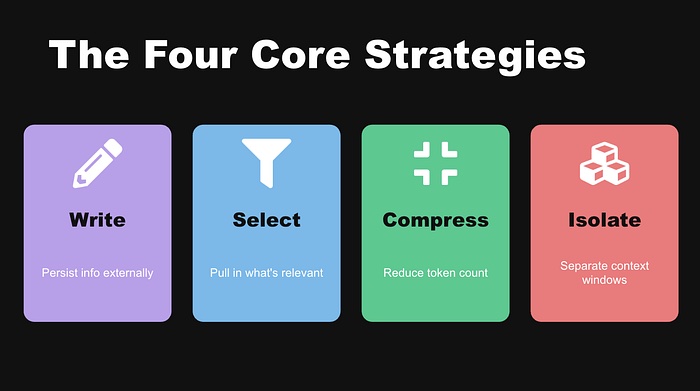
LangChain 发表了一个被广泛引用的框架,将所有上下文工程技术归纳为四类:Write(写入)、Select(选择)、Compress(压缩)、Isolate(隔离)。
3.1 Write(写入)
问题很简单:Agent 会忘记事情。当上下文填满被压缩时,信息就丢失了。
Write 策略就是给 Agent 提供在上下文窗口之外持久化信息的方式。三种形式:
- Scratchpad(草稿板):给 Agent 一个”记事本”工具,让它能在任务过程中记笔记。Anthropic 的 “think” 工具在 tau-bench 基准上提升了最高 54% 的性能。
- 规则文件:如 Claude Code 的 CLAUDE.md。每次 Agent 启动时加载的持久化指令。
- 记忆提取:跨会话保存事实、偏好和学习到的模式。
3.2 Select(选择)
核心思想:不要把什么都给 Agent,只给它当前这步需要的。
传统 RAG 是系统做选择——用户提问,你检索文档,塞进 prompt,一次性管道。Agentic RAG 反过来——Agent 自己决定要搜什么、用什么工具、什么时候信息够了。这是迭代式的检索,因为在多步任务中,每一步所需的信息都在变化。
LangChain 和 Pinecone 区分了 Agent 可以调用的三种记忆:情景记忆(few-shot 示例)、语义记忆(事实仓库)、程序性记忆(行为规则)。
工具选择是一个特别常见的坑。如果 Agent 有 40+ 个工具,工具定义可能占用上万 token。RAG-MCP 论文测试了语义检索工具描述的方案——工具选择的准确率从 14% 提升到 43%,prompt token 减少了一半。
Anthropic 的混合策略:前置加载基础信息(如 CLAUDE.md),其余按需检索。
3.3 Compress(压缩)
即使选择做得再好,上下文还是会累积。压缩就是减少 token 数量,同时保留关键信息。
压缩可以在三个节点进行:
- 信息进入上下文之前:文档分块、重排序、在进入主上下文前先总结工具输出
- Agent 工作中:对话历史总结(保留最后 10 条原文,旧的全部总结)、硬编码裁剪、Claude Code 在 95% 容量时自动压缩
- Agent 执行完动作之后:清理已使用的工具结果(用一行总结替换完整的网页内容)
3.4 Isolate(隔离)
隔离策略让多 Agent 系统成为可能。
如果一个 Agent 试图做所有事——研究、规划、编码、测试、调试——在同一个长对话中,上下文必然会填满。但更深层的问题不是空间,而是污染。研究阶段的详细文件搜索还留在上下文里,当 Agent 进入实现阶段时,这些旧的研究内容就成了噪音。
解决方案是上下文隔离:给不同部分的任务分配各自的上下文窗口。父 Agent 将聚焦的子任务委派给子 Agent,子 Agent 在干净的上下文中工作,只返回精简的摘要。
另一种形式是 LangGraph 的状态 Schema 隔离:工具结果放在”后台”字段,只在需要时才对模型可见。
4. Agent 的四种失败模式
Drew Breunig 在 2025 年中发表了两篇有影响力的文章,识别了 Agent 在上下文增长时的四种失败模式。

上下文中毒:幻觉或错误进入上下文后被反复引用,每次迭代都在错误基础上叠加。修复:主动裁剪过时/冲突的信息,验证工具输出,压缩失败尝试的历史。
上下文分心:上下文过长导致模型过度依赖最近历史,不再独立思考。修复:即使有大的上下文窗口也要积极总结和修剪。
上下文混乱:多余内容被模型捡起来导致低质量响应。最典型的是工具混乱——Agent 看到 46 个工具定义后开始调用无关工具。一个量化的 Llama 3.1 8B 模型在给定全部 46 个工具时失败,但只给 19 个工具时正常工作。修复:动态工具管理,RAG-MCP 语义检索。
上下文冲突:新收集的信息与已有内容矛盾(系统提示说一套,检索文档说另一套)。修复:建立明确的权威排序(系统提示 > 检索事实 > 对话历史),使用结构化章节。
5. 系统提示与工具定义的最佳实践
系统提示
Agent 的系统提示和聊天机器人的完全不同。聊天机器人的系统提示只是设定语气。Agent 的系统提示定义架构——控制流、工具使用规则、错误处理、安全护栏。
Anthropic 提出了”合适的海拔高度”的概念:
- 太具体(”如果用户提到账单且金额超过 100 美元,调用工具 X”)——太脆弱
- 太模糊(”使用合适的工具”)——Agent 没法判断什么合适
- 恰到好处:具体到能指导自主行为,但灵活到让模型在新情境中运用判断力
几个实用建议:
- 用 XML 标签或 Markdown 标题组织系统提示
- 从最小开始,迭代失败——不要预先猜测所有边缘情况
- 最小不意味着短——复杂工作流可能需要数千 token
- 用 few-shot 示例展示好的行为
工具定义
生产中越来越通过 MCP(Model Context Protocol) 处理工具连接。但 MCP 让接入很多工具变得太容易——这正是陷阱。
扩展工具集的两个主流方法:
方法一:工具屏蔽(Manus 推荐)。保持所有工具定义在上下文中稳定(利用 KV-cache),但标记某些工具在当前阶段不可用。不要动态增删工具,因为会破坏 KV-cache——缓存的输入 token 每百万 0.30 美元,未缓存的每百万 3.00 美元,10 倍差距。
方法二:RAG 工具选择。语义检索预选择当前步骤所需的工具。
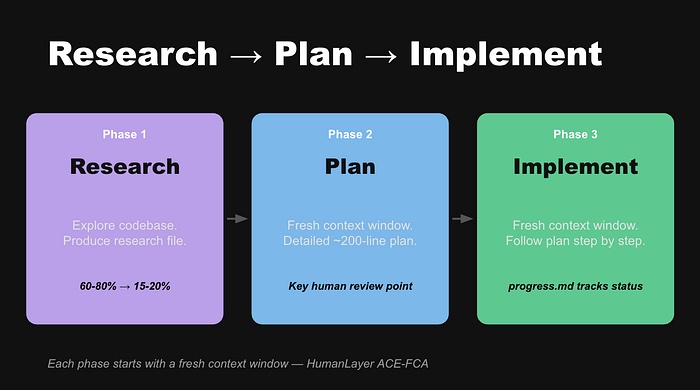
6. 实践:频繁有意识压缩
Dex Horthy(HumanLayer CEO)在 AI Engineer Code Summit 上展示了一个方法论,他的团队据称在单个 7 小时会话中用此方法向大型 Rust 代码库交付了约 35000 行代码。
核心思想:主动将工作组织成阶段,每阶段产出紧凑的产物(结构化 Markdown 摘要),每个新阶段用只包含该产物的全新上下文窗口开始。始终保持在上下文窗口的 40%-60% 以下。
三个阶段:
- 研究阶段:子 Agent 处理原始文件搜索和代码分析。产出研究文件(Markdown,包含文件路径、函数签名、模式、坑点)。使用隔离和写入策略。
- 规划阶段:全新上下文窗口,只包含研究文档和问题定义。产出详细实现计划。这是人工审查的最佳节点。
- 实现阶段:再次新的上下文窗口,只包含计划。对需要多次压缩的复杂任务,用
progress.md跟踪进度。
7. 主流平台的做法对比
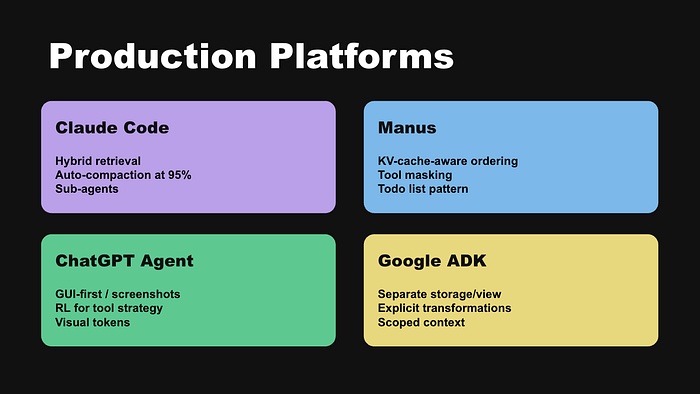
Claude Code
Claude Code 是上下文工程在实践中最有据可查的例子。CLAUDE.md 文件前置加载,使用 glob/grep 等工具按需导航代码库。95% 自动压缩保留架构决策和最近访问的 5 个文件。支持子 Agent 和跨会话记忆工具。Anthropic 的哲学:”做最简单的有效方案”。
Manus
面向数十万用户提供通用 Agent,效率至关重要。贡献:KV-cache 感知的上下文排序、观察压缩管道、持久化待办列表、文件系统作为溢出记忆。
ChatGPT Agent
由 Computer-Using Agent 模型驱动,GUI 优先。截图作为视觉快照加入上下文,视觉 token 昂贵所以必须选择性保留。OpenAI 用强化学习发现最优工具使用策略。
Google ADK
最原则性的架构方法。三个设计原则:存储与展示分离、使用显式转换(命名有序的处理器,可测试、可组合)、默认限定作用域(每个模型调用只看到最少必需信息)。
所有平台最终都遵循相同的管线:收集候选信息 → 选择当前步相关的内容 → 压缩 → 按 KV-cache 复用最大化的方式排列 → 组装上下文 → API 调用。
8. 总结
上下文工程不再是可选技能。随着 Gartner 预测到 2026 年底 40% 的企业应用将集成 Agent,那些掌握上下文工程的团队才能真正让 Agent 可靠工作。
核心心法就四个词:写入、选择、压缩、隔离。每次遇到 Agent 出问题,先想想是这四种失败模式中的哪一种——中毒、分心、混乱还是冲突——解决方案自然会落到四个策略之一。
最好的学习方式就是自己动手试。