Agentic AI 安全模式:AI 网关、OAuth2 令牌交换与 MCP 防护
背景
Agentic AI 系统的核心特征是自主性和推理能力——它们能将复杂任务分解为可执行的子任务,编排执行流程,并在执行过程中监控、反思和自适应修正。
这意味着几乎每个企业业务流程都可以被”agent化”:从客服台到 HVAC 优化,甚至用 agent 搭建软件、数据和 ML 工程管道。但一个关键问题随之而来——安全。
传统应用的安全模型在 agentic 场景下完全不够用。AI agent 不是人,不遵循 HR 流程,也没有”问责”的概念——一个 agent 出错可能导致整个执行链崩盘。
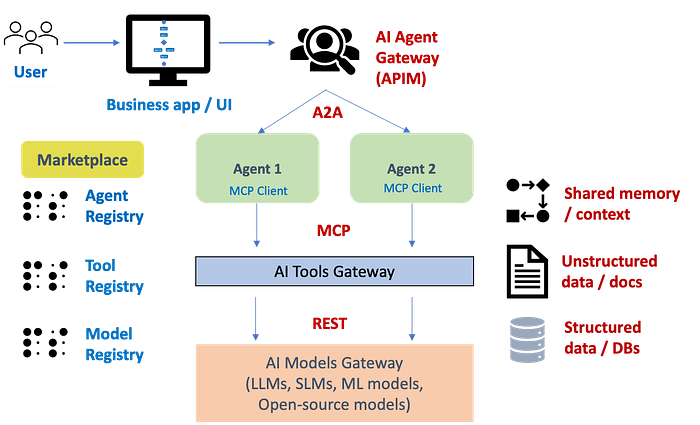
Agentic AI 参考架构
要理解安全模式,先看架构。一个完整的 agentic AI 平台包含以下关键组件:
- 推理层:分解复杂任务,自适应调整执行策略
- Agent 市场/注册中心:存管可用 agent、工具和模型的目录
- 编排模块:协调多 agent 系统的执行和监控
- 集成模块:通过 MCP 协议连接企业系统(ERP、CRM、知识库)
- 共享内存管理:跨 agent 的数据和上下文共享
- 治理层:可解释性、隐私、安全、防护栏
当用户提交任务时,平台需要找到合适的 agent(或 agent 组)来执行。Chain of Thought(CoT)是目前最广泛的任务分解框架,而 ReAct(推理+行动)允许 agent 评估自己的输出、从中学习、修正推理路径。
Agent2Agent(A2A)协议定义了 Agent Card(JSON 格式的”数字名片”),包含身份标识、服务端点、协议能力、认证方式和技能列表。这为 agent 注册和发现提供了标准化方案。
MCP(Model Context Protocol)则被用作系统集成层的基础,类似 AI 模型的”USB-C”接口。它定义了三个核心构件:
- Resources:服务器提供给 AI 的结构化数据(代码片段、文档、查询结果)
- Prompts:预设的指令或模板
- Tools:AI 可以调用的实际操作
安全模式一:应用到 Agent(AI 网关模式)
用户/应用与 agent 之间的交互通过 AI 网关 来保护。架构如下:
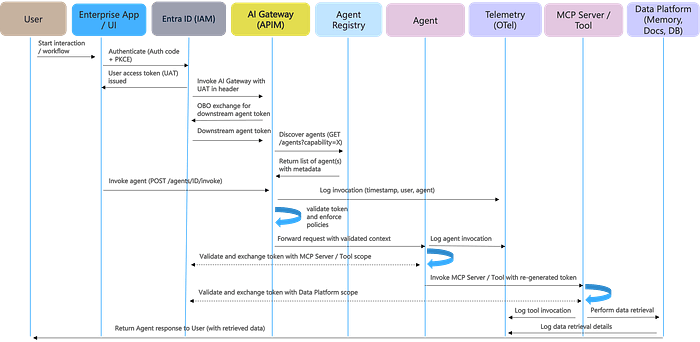
核心流程:
- 用户在业务应用中发起交互
- 应用通过 授权码 + PKCE 向 Entra ID(或其他 IAM)认证用户
- Entra ID 签发用户 access token
- 应用将 token 放入请求头调用 AI 网关
- AI 网关执行 On-Behalf-Of(OBO)交换,获取下游 agent token
- 网关校验 token,执行策略(JWT 验证、角色/作用域检查)
- 网关将已验证的上下文转发给 agent
- Agent 在自身层面进行二次授权
- Agent 执行业务逻辑并返回结果
- AI 网关和 agent 都将调用日志写入 OpenTelemetry 平台
关键点:token 不可传播。agent 收到的 token 只针对该 agent 本身,不能被用来调用其他 agent 或 MCP 服务器。
安全模式二:Agent 到 MCP 工具(令牌交换)
当 agent 需要调用工具来完成任务时,它通过 MCP 协议与工具服务器交互。这里的关键安全机制是 OAuth 2.0 令牌交换(Token Exchange, TE)。
为什么不能直接传播 token?
两个原因:
- 溯源性:如果 token 被传播,下游工具无法分辨请求是来自 MCP 服务器还是原始应用
- 作用域:收到的 token 权限范围可能与 MCP 服务器需要的不匹配
令牌交换流程
- Agent 收到用户/应用传来的 access token(此 token 的
aud声明标识 agent 本身,sub声明标识原始用户) - Agent 需要调用工具,向认证服务器的 token 端点发起令牌交换请求,携带:自己的凭证、收到的 access token、新 token 的目标作用域和受众
- 认证服务器校验请求,签发一个缩小作用域的新 access token,明确指向目标 MCP 服务器(
sub声明仍保持原始用户身份——保留用户上下文) - Agent 用新 token 调用 MCP 服务器
对于长时间运行的批处理任务(没有用户上下文),使用 客户端凭证授权(Client Credential Grant, CCG)——这是为机器对机器(M2M)通信设计的 OAuth 2.0 流程,完全不需要用户交互。
端到端安全模式
完整的端到端流程涵盖:用户 → 应用/UI → AI Agent → MCP 服务器/工具 → 数据平台。
每一步跨越安全域时都要做一次令牌交换。这不是可选的——是为了防止 token 越权传播、保证审计链路完整。
安全模式三:Agentic 防护栏(Guardrails)
光有认证授权还不够。作者整合了 OWASP 和 IBM 两份白皮书中的风险清单:
风险分类
对齐与行为风险
- R1:对齐失败与欺骗行为(动态欺骗)
- R2:意图破坏与目标操控(目标不一致)
- R3:工具误用(工具/API 滥用)
- R4:记忆中毒(Agent 持久化)
- R5:级联幻觉攻击(级联系统攻击)
安全漏洞
- R6:权限泄露
- R7:身份伪造与模仿
- R8:意外 RCE 与代码攻击
运营韧性
- R9:资源过载
- R10:抵赖与不可追溯
多 Agent 合谋
- R11:多 Agent 系统中的恶意 Agent
- R12:Agent 通信投毒
- R13:人类对多 Agent 系统的攻击
人类监督
- R14:人类操控
- R15:人机环路过载
- R16:角色驱动偏见(IBM 特有)
风险映射到架构
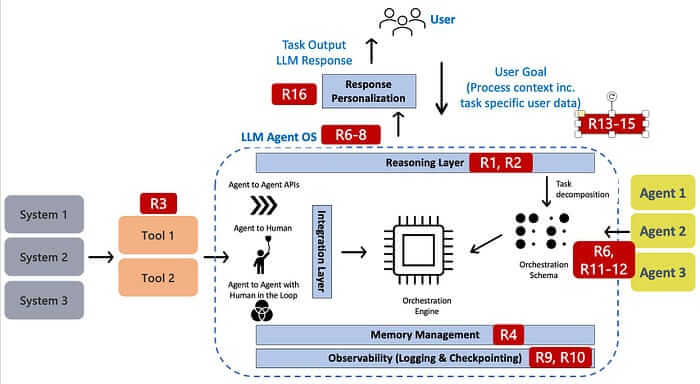
重要的是,防护栏不能只丢给一个中央治理层。不同的风险需要在其对应的架构层进行管控:
- 推理层:处理对齐失败、意图破坏
- 工具集成层:处理工具误用、RCE
- 内存层:防止记忆中毒
- 编排层:管理多 Agent 合谋、资源过载
- 用户接口层:处理人类操控、环路过载
总结
Agentic AI 的安全仍处于早期阶段,但重要性与日俱增。随着 agent 开始执行带记忆的长任务、在多 agent 场景中协作、处理越来越复杂的数据工作流——现在就开始将安全设计融入架构中,比以后补救要明智得多。
核心原则:零信任 + 最小权限 + 每次跨域做令牌交换。
版权所有,本作品采用知识共享署名-非商业性使用 3.0 未本地化版本许可协议进行许可。转载请注明出处:https://www.wangjun.dev//2026/06/agentic-ai-security-blueprints/